

For the last three months, I have been working with researchers from across the physical sciences at the University of Sussex on some software to classify videos of court cases as either deceitful or truthful. Building on work by Yusufu Shehu, we have constructed a neural network (a type of software partly inspired by neurons in the human brain) that can classify these videos with an accuracy of over 80%. Figure 1 shows our network design. For comparison human ability to spot lying is often below 60%. The software could in theory be trained on other data sets and we are actively looking for people in commercial areas who might be interested.
One interesting aspect of neural networks is that we don’t tell the network how to work, but rather we train it. This means that the network could be trained on other features. Any combination of video, audio, and text can in principal be classified into any sets where there is information in the data. Some possible ideas for how this might be applied in other situations are classifying phone conversations according to the emotional tone or likelihood of a successful sale. Classifying music into genres, speakers by gender or age, specific speakers for security reasons. Figure 2 shows some clips form the court case videos. A court case is a very particular environment so we are interested to apply the software to other settings.

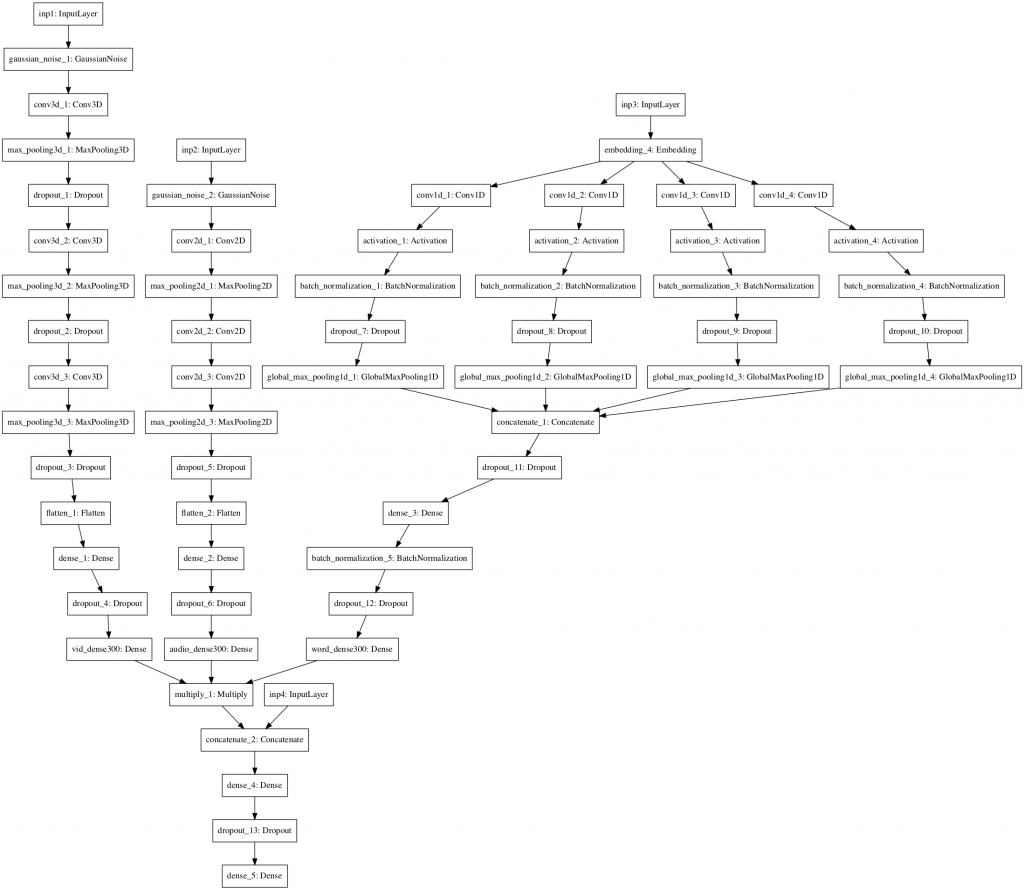
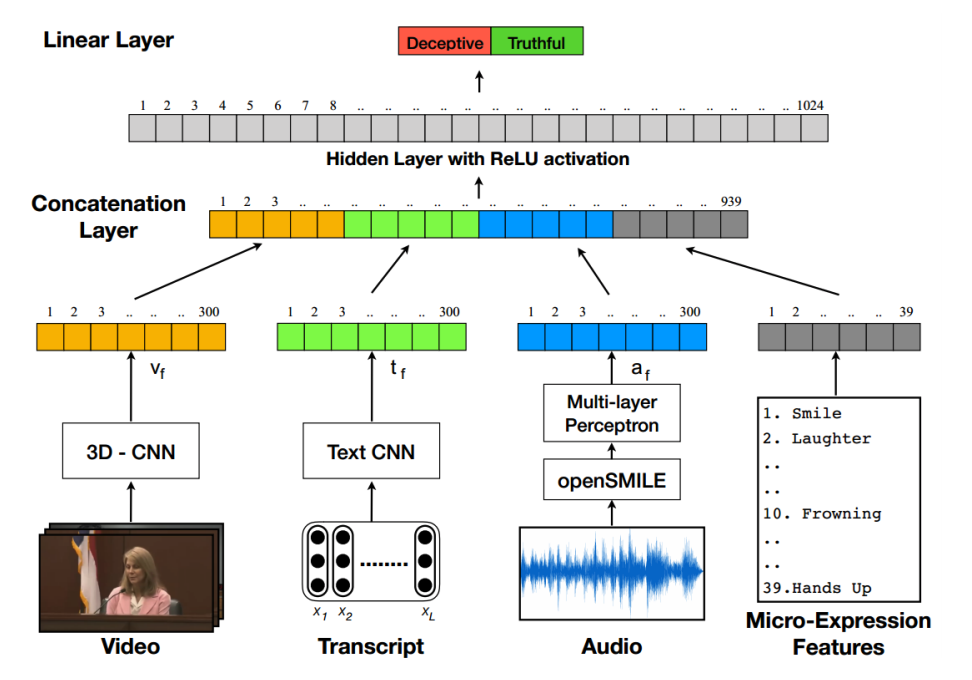
A paper in 2018 by Krishnamurthy et al. developed a ‘multi-modal neural network’ and trained it on 120 court case videos taken from the Miami University deception detection database (Lloyd et al. 2019). They showed that it was possible to detect deception with an accuracy of 75%, a significant improvement on human performance. We have further developed their model and achieved improved results. In the multi-modal network video, text transcripts, audio and ‘micro-features’ are treated independently and then the results are combined to get a final probability. Figure 3 shows how the network is designed.
We are interested to have conversations with potential industry partners who might wish to take this forward with us. Please don’t hesitate to get in touch if you think this research could be useful to you. We are interested in applying these networks both to video and also to audio only. We see particular possibility for collaboration with an industrial partner in an area that relies on large volumes of audio data from, for instance, telephone calls.